







 Flash プロの現場の仕事術 CS5/CS4/CS3対応
Flash プロの現場の仕事術 CS5/CS4/CS3対応 体系的に学ぶ 安全なWebアプリケーションの作り方
体系的に学ぶ 安全なWebアプリケーションの作り方 ケータイHTML ポケットリファレンス
ケータイHTML ポケットリファレンス 携帯サイト年鑑2010
携帯サイト年鑑2010 携帯サイト コーディング&デザイン
携帯サイト コーディング&デザイン 携帯Flashスクリプト入門
携帯Flashスクリプト入門
 ブックレビュー:ユーザー視点でつくる 携帯サイト制作の基礎知識
ブックレビュー:ユーザー視点でつくる 携帯サイト制作の基礎知識 札幌のソーシャルゲーム開発なら
札幌のソーシャルゲーム開発なら

 ソフトバンクの絵文字を検出する正規表現
ソフトバンクの絵文字を検出する正規表現

 Tweet
Tweet
先日ご紹介した、「iモードの絵文字を検出する正規表現」に続き、ソフトバンク編です。
ソフトバンク絵文字を表す正規表現は次の通りです。
[\\x1B][\\x24][G|E|F|O|P|Q][\\x21-\\x7E]+[\\x0F]
絵文字が連続して続く場合は、頭の3バイトとお尻の1バイトは省略でき、真ん中の1バイト部分のみとなることに注意してください。
ややこしいのですが、この仕様はバイト数削減のためなのでしょうか。
例:絵文字が続く場合のサンプル(男の子の顔と女の子の顔を表示)
[0x1B][x24]G!~[0x0F]
なおソフトバンクは、端末によってフォームからの絵文字仕様が異なります。
- 上記の絵文字コードを送ってくる(UTF-8のみ対応の場合や、一部コード化されることも)
- 絵文字を外字領域のコードに変換して送ってくる
- 絵文字を全角スペースに変換して送ってくる
- 絵文字を削除して送ってくる
というパターンがあるようです。
(なんと古い端末にはバグのため、上記仕様を完全に実装できてない場合もあるそうです)
詳しくはソフトバンクの技術資料PDFに記載されています。
→ ソフトバンク 技術資料 [softbankmobile.co.jp]
※ウェブコンテンツ開発ガイド[HTML編] 端末→Webサーバの項 (33ページ付近)
手元の「705SH」でテストしたところ、2のパターンに該当するようです。
この場合は、外字のGL領域を削除してやればよいので、iモードに近い方法で削除が可能です。
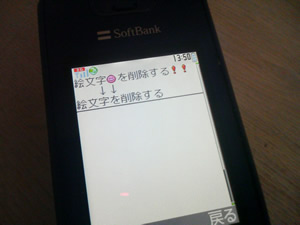
HTMLはSJISで作成しています
とにかくソフトバンクの絵文字はややこしいです。
もう少し詳しく調べたら、また記事にまとめたいと思います。
関連:
3月 19th, 2008 at 14:37:32
正規表現において、\\x1b 等の1文字だけをブラケットでくるんであるのと、GEFOPQ の合間に | を入れているのが不思議なのですが、何か理由があるのでしょうか。
\\x1B\\x24[GEFOPQ][\\x21-\\x7E]+\\x0F
で十分動くと思います。
3月 19th, 2008 at 19:13:20
yurikoさん
コメントありがとうございます。
なるほどおっしゃる通りですね。
この記事を書く際に参考にさせて貰った私の好きなウノウラボさんのサイトでそうなっていたからで、特に深い理由はありません。
http://labs.unoh.net/2007/01/softbank_1.html
確かに冗長かもしれないですが、正規表現には色々な書き方がありますしご容赦ください。
ご指摘ありがとうございました。
3月 20th, 2008 at 16:02:22
なるほど、参考資料がそうなっていたのですね。GEFOPQ の部分は、選択を使って
(G|E|F|O|P|Q)
ならば、| で区切るのは自然なのですが、文字クラスを使って
[G|E|F|O|P|Q]
と書く場合、| を入れてしまうと | 自体もマッチ対象になってしまいます。実際には、ESC $ の直後に | が来ることはあり得ないので、問題はないのですが。
正規表現はいろいろ書き方があるのは理解していますが、今回のは「文字クラスの文法を分かってない」ように見えるため、非常にはずかしくなっているんですよ〜〜。